
光学神经网络迈向广泛实用性的挑战与前景
光学神经网络有望实现前所未有的效率、带宽和延迟优势——在人工智能算力需求激增的背景下,这些优势至关重要。然而,其在通用加速或专用应用领域的实际价值仍需在贴近真实应用场景的条件下验证。法国玛丽与路易·巴斯德大学Anas Skalli和Daniel Brunner近期在Nature Photonics上发表的论文(20(6): 601-604, 2026),系统梳理了光学神经网络在通向广泛实用性道路上面临的核心挑战与关键研究方向。

一、光学神经网络的潜在优势与现实困境
光学神经网络再次站上技术创新的前沿,十多年来光子储层计算和集成光学神经网络持续引发关注。与电子系统上的人工神经网络相比,光学神经网络在并行性和信号转导方面具有更高潜力。然而,它们在现实世界的部署仍受到技术障碍的制约——尽管多年研发投入,该领域尚未充分发挥其潜力。
正如约翰·梅纳德·凯恩斯所观察到的:"我们寻求促进的事态应该比之前的事态要好是不够的;它必须足够好,以弥补过渡的弊端。"研究团队从这一视角出发,审视了光学神经网络从概念验证到实际相关性之间所面临的细线型挑战。
二、核心计算原理与性能瓶颈
人工神经网络的核心计算瓶颈在于矩阵-向量乘法(MVM)操作。在密集连接的两层网络中,对神经元数量N而言,线性操作量为O(N²),而非线性激活仅线性增加O(N),因此MVM运算在计算负荷中占主导地位。光学矩阵-矢量乘法之所以有前景,在于其原则上可在高带宽、低延迟和极低功耗下实现大规模并行乘法-累加操作。
然而,当前集成光子MVM引擎的尺寸仍远低于最先进人工神经网络中使用的矩阵维数。将大矩阵(N×N)平铺为小矩阵(L×L)后,系统级成本变为O((N/L)²),且每次平铺都涉及光学表现尤为薄弱的接口操作。这一被广泛忽视的事实有可能使光学计算在功耗方面的优势化为乌有,除非集成光子平台能够实现比目前更接近N的矩阵-矢量乘法维数L。
三、通用加速与专用架构的分野
论文区分了两条技术路径:
通用光学人工神经网络加速器:将经典的人工神经网络模型忠实地映射到矩阵向量乘法电路的拓扑结构上,可以使用标准机器学习工具(包括误差反向传播)实现最先进的网络架构。代表平台包括马赫曾德网格、环形谐振网络和光子忆阻交叉开关阵列。
专用光学神经网络:通过直接利用硬件的基本变换进行计算,通常会结合光学非线性。代表实例包括光学储层计算、尖峰光学神经网络和具有最小预处理或后处理的自主光学神经网络。其目标是在光学域中直接执行计算,最大化系统级别的速度和效率优势。
四、四大关键挑战
(一)能效声明的系统级验证缺失
当前能效声明通常基于单个组件或高度简化的系统配置,而非完整系统性能。当包括现实的架构要求时,大部分预计的扩展优势往往会消失。直到光学加速器在完全集成的操作架构中的应用条件下得到证明前,外推结果仍属推测性。
(二)超高带宽的实际限制
光学神经网络的速度优势只有在以THz带宽实时传输输入数据时才能实现。而输入数据在许多情况下是通过光电调制器以电子方式提供的。断言单通道大于100 GHz电光调制器可大规模部署在大型系统中,往往忽视了具体的光子集成策略、额外能源成本以及缺乏能够以所需吞吐量驱动这些调制器的电子总线架构。
(三)组件级性能到系统级集成的鸿沟
源自单个高度专业化光子组件的"连接主义"主张通常被外推到整个系统性能。然而,实践中具有高性能的单个组件在大规模应用时往往不符合要求——例如尖端谐振器中的光子非线性,其性能只有在极高的品质因数下才能实现,但制造非理想性和温度梯度使多个谐振器间的耦合实际上难以实现。
(四)训练成本被系统性低估
光学神经网络通常与基于误差反向传播的标准训练方法不兼容,黑盒和无模型学习方法虽提供了替代方案,但训练能耗如何随网络规模变化仍未被探索。光子人工神经网络加速器在训练过程中通常需要额外努力来解释较低的分辨率和设备漂移,"训练一次,长期利用"的说法往往过于简化了实际的成本动态。
五、通往实用化的技术路线
论文为光学神经网络的未来发展提出了清晰的路线图。对于光学人工神经网络加速,优先开发和演示更大、可能非常规的光学MVM引擎,而非优化单个元素。同时需要设计高性能的数字电子到光学接口,以及探索快速和高维电光调制的新方法。对于专用光学神经网络架构,应更加重视以协同和可编程的方式实现包括数据注入、非线性变换和读出机制在内的完整系统。
值得注意的是,自由空间光学系统目前代表了解决其中几个架构瓶颈的最新技术。而三维光子集成被论文作者认为是唯一能够实现密集连接网络可扩展集成的策略——在光子三维电路中,主要损耗是散射而非吸收,有源元件可放置于表面以实现高效散热,这一特性克服了三维电子学中的热管理瓶颈。
六、展望
随着人工神经网络的社会意义和广泛采用持续增长,对其可扩展性和能耗的担忧成为核心议题——英伟达和台积电目前都在正式探索光子集成。研究团队强调,可信的进展要求以下三个方面:在现实的人工神经网络条件下进行系统级验证;明确针对大规模MVM维数、高带宽数据注入和协同设计的技术路线图;区分通用加速和专用光学神经网络计算的特定应用关键性能指标。
尽管取得了重大进展,提供光子人工神经网络计算既不是短期的竞赛,也不是过去光学计算周期的重复。它需要研究人员、资助者和行业之间的深度合作。如果条件成熟,光学神经网络最终可能从优雅的概念验证演示发展到不可或缺的技术——前进的道路仍然很窄,但科学、经济和社会潜力足以证明这一长期努力的合理性。
参考资料:
[1] Skalli A, Brunner D. The thin line for optical neural networks towards broad practical relevance. Nature Photonics, 2026, 20(6): 601-604.
-

VR/AR光学检测全景指南:从光波导到整机成像质量的技术解析与设备方案
随着Apple Vision Pro、Meta Quest系列等产品的持续迭代,VR(虚拟现实)和AR(增强现实)已从概念验证阶段迈入规模化量产。然而,VR/AR光学系统的复杂性远超传统成像镜头——菲涅尔透镜的杂散光控制、光波导的衍射效率均匀性、Pancake方案的偏振性能,每一项都对光学检测提出了全新的技术挑战。本文系统梳理VR/AR光学检测的核心技术难点、检测参数体系以及适配不同产品形态的设备方案,为VR/AR光学制造商和研发机构提供实用的参考指南。
2026-07-24
-

手机镜头与车载摄像头MTF检测:从研发到量产的光学质量保障方案
在智能手机多摄化、车载摄像头智能化的行业趋势下,光学镜头的成像质量直接决定了终端产品的用户体验。MTF(调制传递函数)作为衡量光学系统成像性能的核心指标,已成为从镜头设计到量产交付全流程中不可或缺的检测环节。本文将围绕手机镜头和车载摄像头两大应用场景,系统介绍MTF检测的技术原理、关键挑战以及适配不同生产阶段的设备方案。
2026-07-24
-
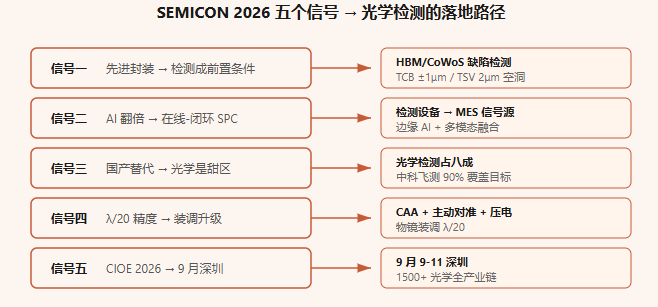
万亿美元前夜:SEMICON China 2026给光学检测的5个信号
3 月底的 SEMICON China 2026 把"AI 算力"推到了 C 位。SEMI 中国总裁冯莉在开幕主题演讲里抛了一组数:2025 年全球半导体销售 7917 亿美元,2026 年预计 9750 亿,原定 2030 年才到的万亿美元节点,大概率要提前四年撞线。
2026-07-24
-
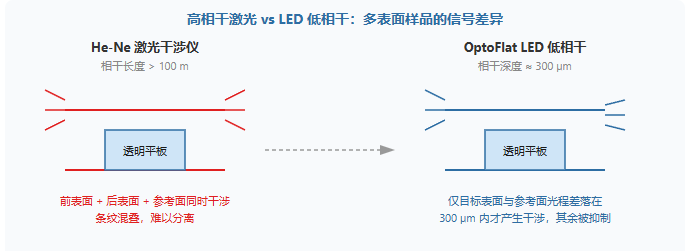
OptoFlat® 低相干干涉仪:平面光学件的“透明陷阱”怎么破
测一块双面抛光的晶圆或光学窗口,激光干涉仪的屏幕上经常飘出一团“鬼影”——前后表面同时出条纹,参考面和被测面互相抢戏,最后连 PV 值该信哪一面都说不清。OptoFlat 要做的,就是把这个“透明陷阱”关掉。
2026-07-23
-

光学窗口与平板件的平行度与透射波前检测
在激光防护窗口、红外热像仪保护窗和干涉仪分光镜中,一块看似"平整"的光学平板承载着不亚于透镜的精度要求——平行度3角秒、透射波前λ/10。平板光学件的检测与透镜检测有本质区别:没有光焦度意味着传统的焦距法和自准直法不再适用,而"平行度"和"透射波前"这两个参数也不像面形PV那样直观易懂。本文从平行度和透射波前两个核心指标出发,系统介绍平板光学件的精密检测方法。
2026-07-22







